


Getting Started with Regular Expressions

Regular Expressions are an essential skill for any developer. We can do various tasks with them, whether to define a text pattern or search for text pattern in a larger text notes, it will come handy.
Here in this article, I will be explaining the fundamentals, that you should know, to get started with Regular expressions.
Things to note before going through this article:-
1.) The term ‘Regex’ will be used frequently, which is common term to refer Regular Expressions. 2.) Regular expression is not a programming language, its a tool, to enhance our speed while coding or searching for a text pattern. 3.) Which ever language you may use, be it C#, Java, JavaScript, Python, PHP, Ruby etc., you will find regex everywhere, wherever applicable. 4.) We need to correctly define the text or text pattern, using symbols and rules in order to work with regex. 5.) In order to practice regex, you can use some intelligent text editor like Notepad++, Atom etc. Or even there are online web tools or apps available, you can try regexr.com, a great tool for regex.
Commonly used examples for Regex include, validating credit card numbers, email addresses etc.
So, lets get started.
Notation
In many of the languages, we may need to use delimiters(//), surrounding the regex, like /xyz/. Although the forward slashes are not part of the regex, but they are used to mention, that this is a regular expression and not a regular string.
Special Characters
Below are some special characters to note for now, we will use them as we go through. 1.) Spaces (literal space) 2.) tabs (\t) 3.) line returns (\r, \n, \r\n)
Flags/Modes
Below are some flags, and how they are used in regex. 1.) /g (global flag):- to tell the regex engine, that the expression we are defining, should be used globally, and find all the matches throughout the document. without this, it will find the first match only.
2.) /i (case insensitive) :- to find match regardless of its case.
3.) /m (multi line) :- if a text stretches to multiple line, we can use this flag, to match that, by default the search will be single line only.
Matching Literal Characters
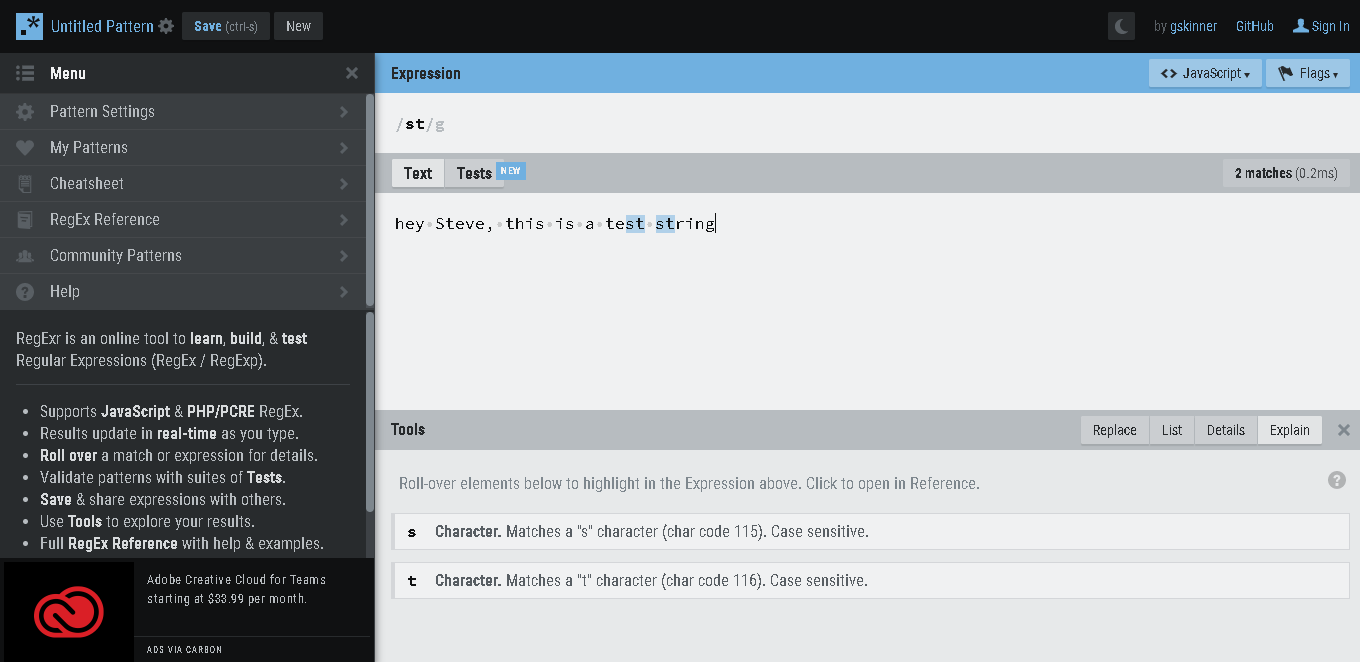
Matching Literal Characters Its the simplest form, we can use to match any string. For example:- 1.) we have a text:- “this is a test string” and we want to match ‘st’, in this note. then the regex we can write will be :- /st/ it will return the first match, in the word ‘test’. Have a look below.
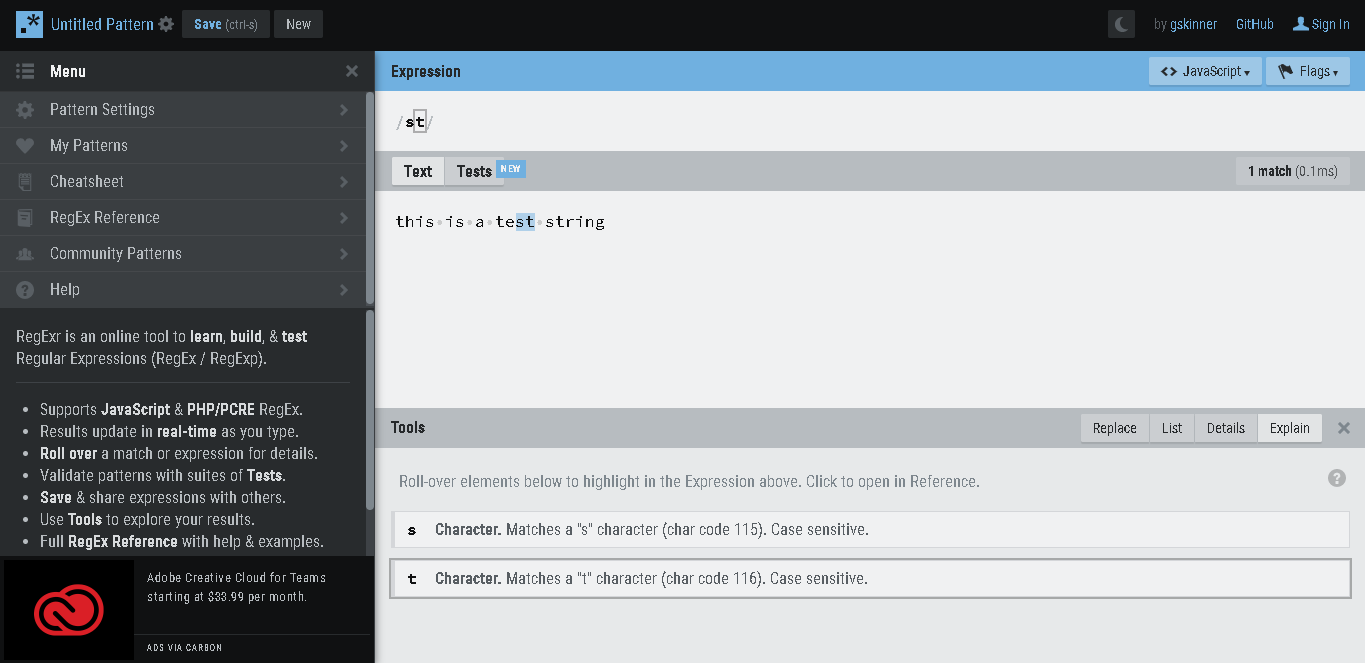
And if we do the match globally, the regex will be :- /st/g it will match both ‘st’, in ‘test’ as well as in ‘string’

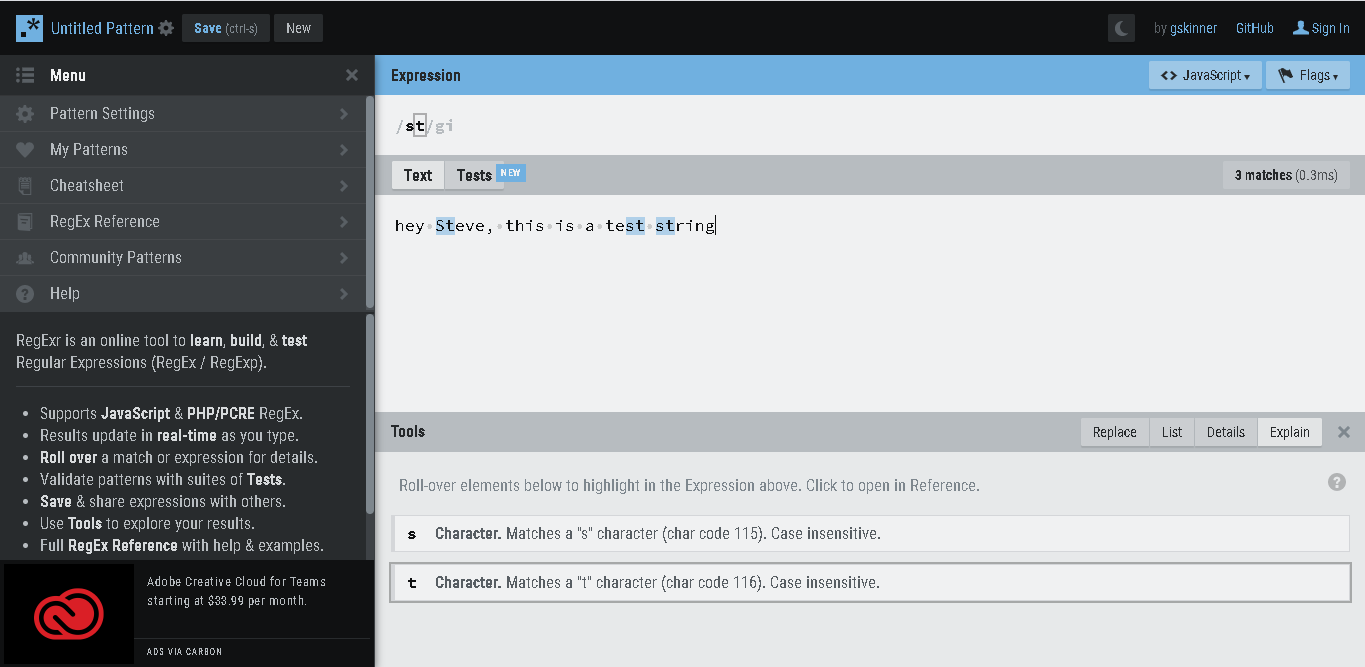
2.) let say we had the text like following :- “hey Steve, this is a test string” and we still use the regex /st/g, it won’t find the first match ‘St’ in ‘Steve’.
we will have to modify our regex as :- /st/gi Having the flag ‘i’, at the end, now it will do case insensitive search, and will match all. take a look below:-
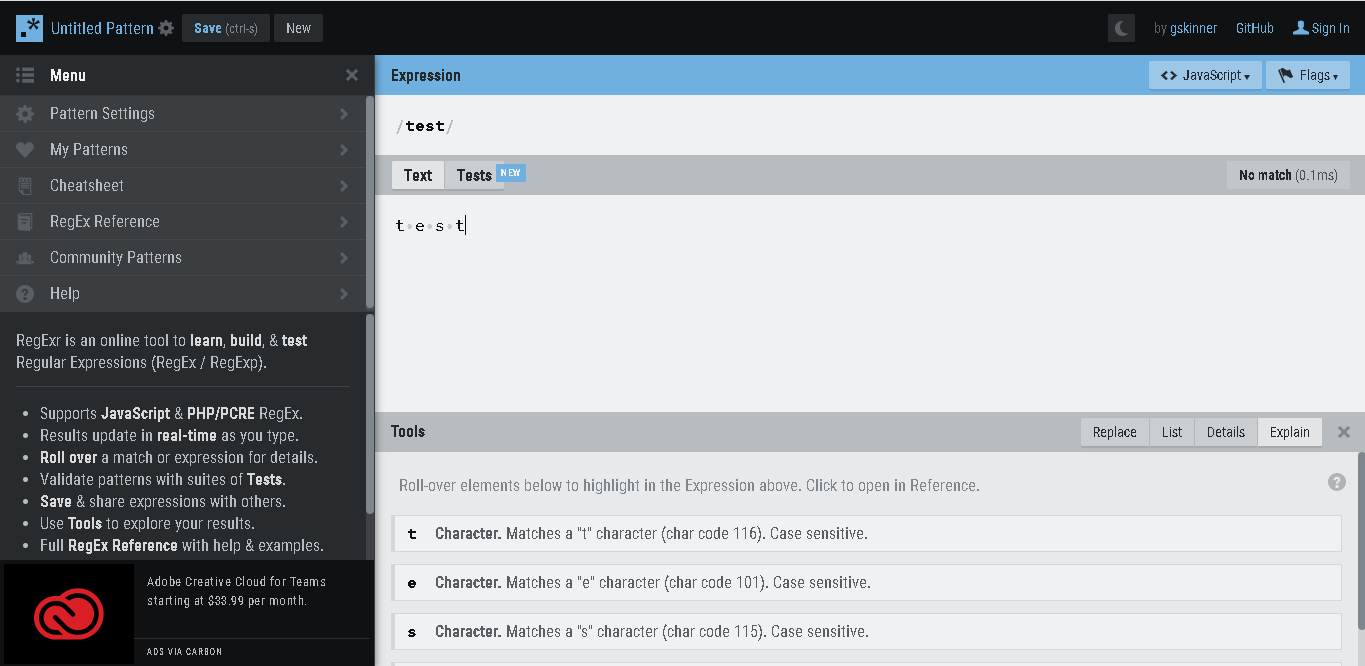
3.) Space is also treated as a character. for e.g. our string is :- “t e s t” and regex:- /test/ it won’t find a match
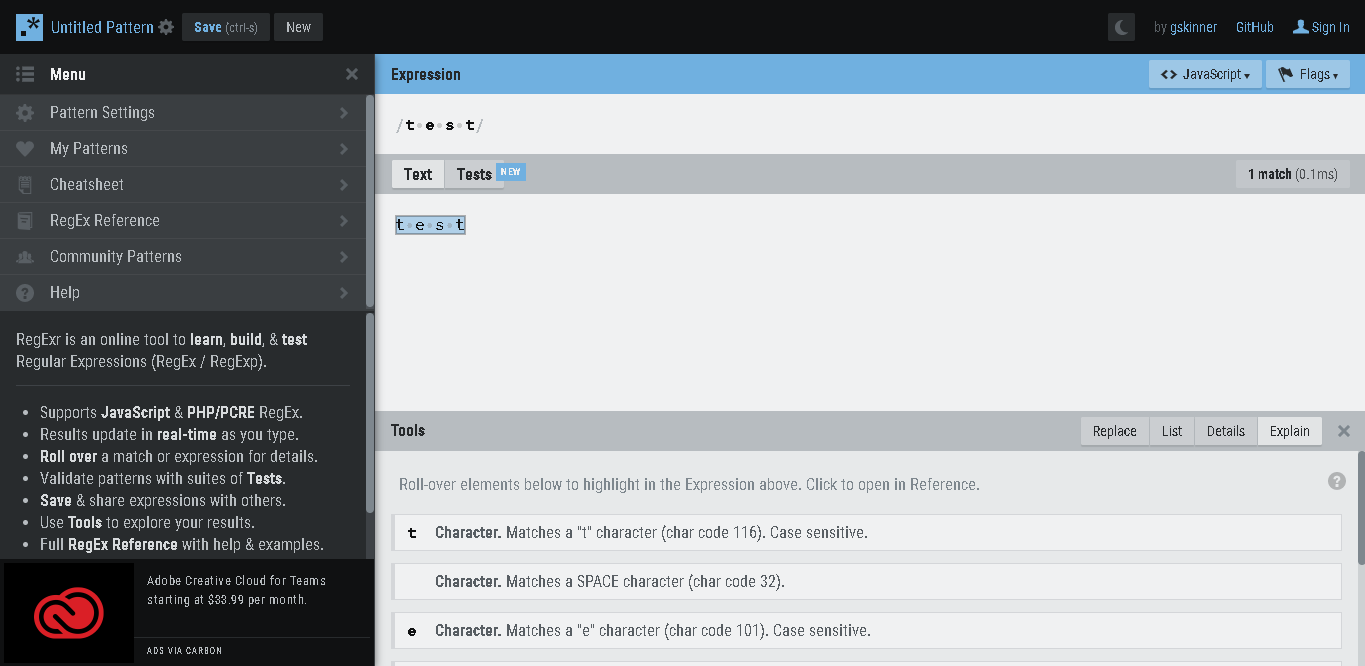
in order to match, say ‘t e s t’, we need to change regex as /t e s t/ then it will match., have a look below.
Meta Characters
These are the characters with special meaning. The most commonly used are:-
- . (dot or period),
- [] (square brackets)
- \ (back slash)
There are few more, that we will see going through.
. (Dot or Period or wildcard)
If used, it matches any character, except the new line.
For e.g. our string might look like :- top, tap, tip and to match all of them with a regex, we can write regex like :- /t.p/g it says, match string having first character as ‘t’, then any character except new line and then ‘p’.
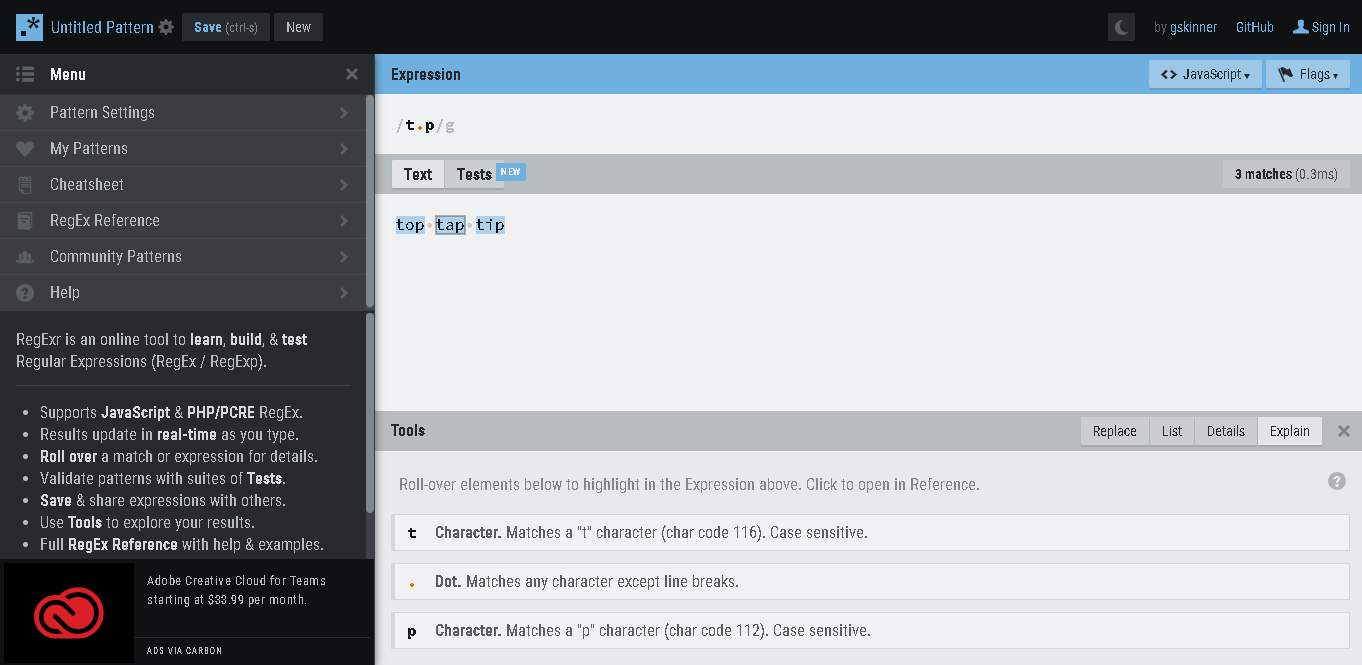
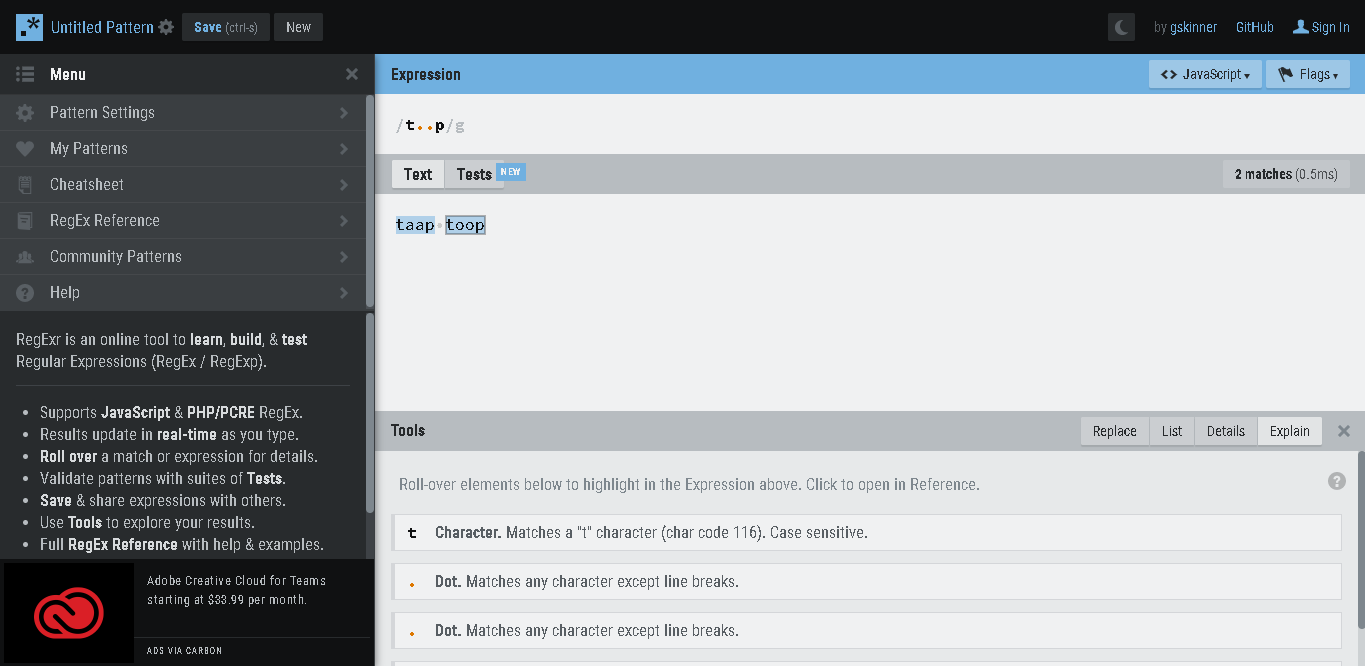
But, the regex won’t match ‘taap’ or ‘toop’, as dot matches for a single character only. To get 2 char in between, we need to write /t..p/.
Mistakes to avoid with wild character
If we want to literally match ‘.’, for e.g. ‘.’ in 5.45, and we write regex as :- /5.45/, will that be correct? No, it will match :- 5.45 as well as 5045 or 5–45 etc.
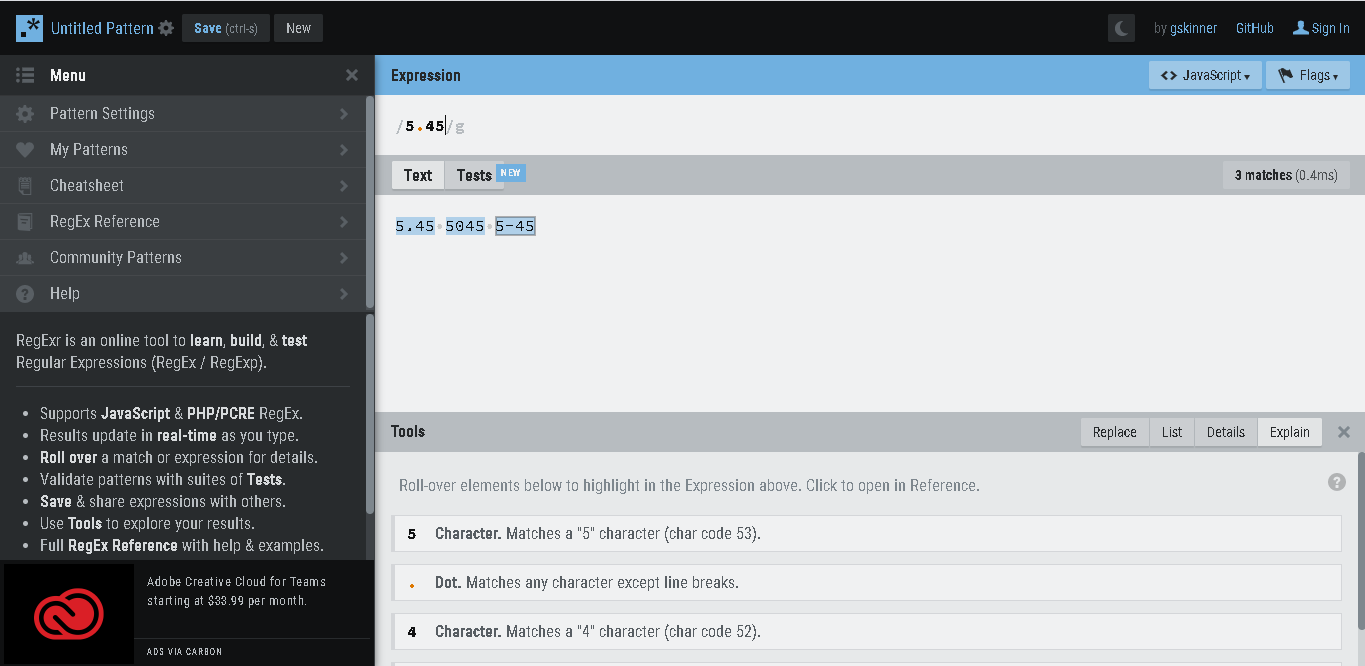
To match only in 5.45, we need to escape ‘.’, like /5.45/, using backslash, it will work.
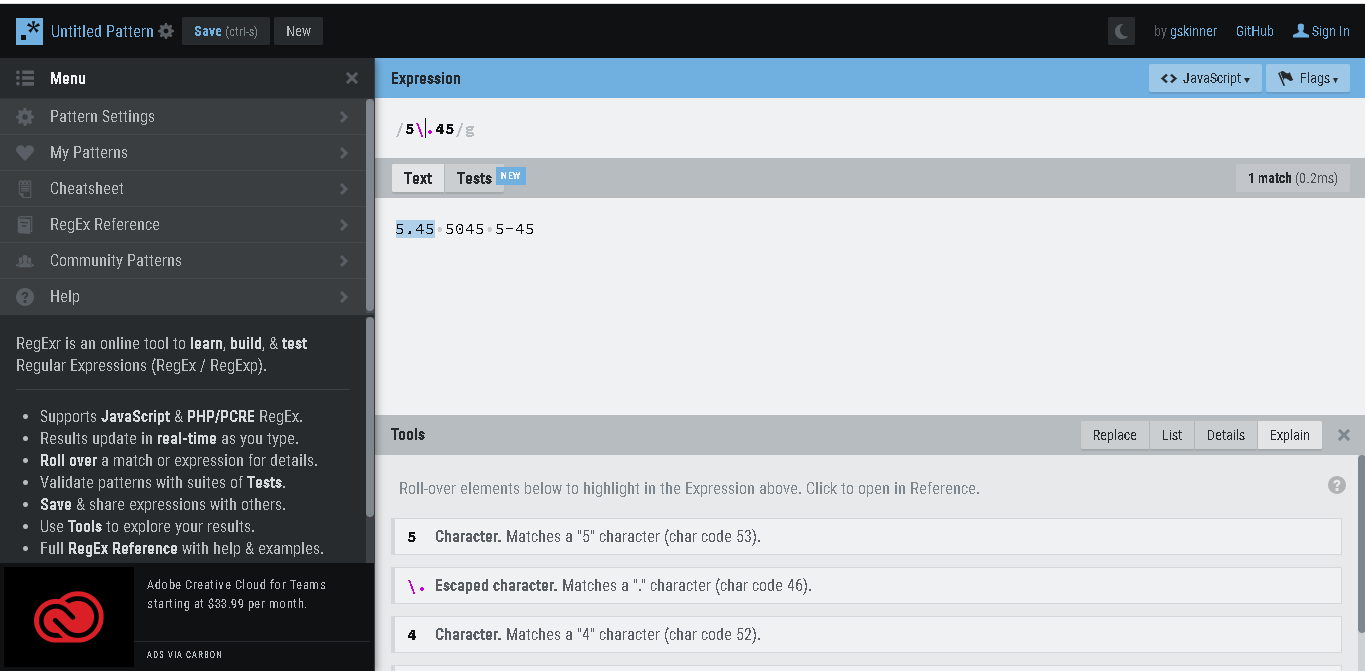
\ (backslash)
We have already used it in previous example, its the 2nd meta character, that we are going to learn.
Its used to escape next meta character, and allows to treat that as a regular literal character.
For e.g. /5.45/, will treat ‘.’ as meta character, but /5.45/ will treat ‘.’ as a literal.
Mistakes to avoid we should always escape meta character only, and not regular literal character, as it may give them some other meaning.
Thanks for reading this article, we will continue this topic in upcoming articles. Stay tuned.